Se você chegou aqui é por que teve a mesma dúvida que eu: como e por que a Wikipédia aparece em primeiro, ou no top 3, de tantas buscas no Google?
Como foi dito, a Wikipédia domina o Google principalmente por causa de sua autoridade de domínio incrivelmente alta, mas ainda existem outros fatores que fazem parte do sucesso da enciclopédia online mais conhecida do mundo.
Vamos tentar entender o que faz deste portal um grande competidor para várias palavras-chave, e se existe justiça no posicionamento alto de tantas páginas desse domínio. Confira!
Domain Authority
Em sua busca por entregar o melhor resultado possível para seus usuários, o Google avalia vários fatores antes de decidir a ordem das respostas ideais para a palavra-chave pesquisada.
A autoridade de domínio, ou domain authority, desponta como um dos que mais pesam para mostrar à ferramenta de pesquisa que um site vai entregar um resultado satisfatório. E os resultados de buscas mostram isso.
Perceba como o ranqueamento tende a ser melhor a medida que a autoridade de domínio cresce.
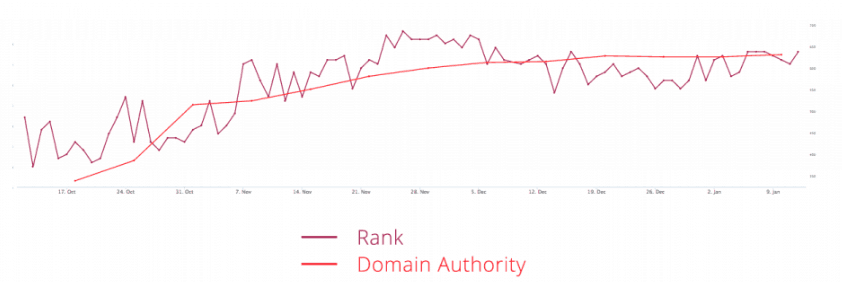
Isso é um grande fator para justificar a dominância da Wikipédia nas páginas de busca, afinal, estamos falando de um domínio que tem 92 em uma escala de 1 a 100, e que chega a impressionantes 97, em sua versão em inglês.
Neste ponto você pode estar se perguntando como cheguei a um número tão preciso. Bem, por sorte temos maneiras muito simples (e gratuitas) de checar o Domain Authority. A mais simples e confiável é usando a MOZ Bar.
Essa ferramenta apresenta com precisão dados como autoridade de domínio, autoridade de página (voltarei nesse assunto adiante), links No-follow e Follow, links externos e externos, entre outros recursos.
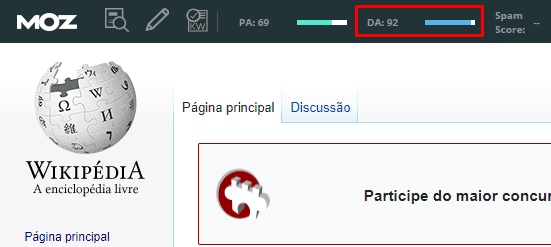
E foi ela que me contou esses e outros dados que vou usar para embasar alguns pontos deste post.
Mas como eles chegaram a um número tão alto?
O que aumenta a autoridade de um domínio?
Vamos a alguns fatores que levados em consideração para calcular a autoridade de um domínio:
Links externos
Imagine que você está escrevendo um artigo sobre futebol para um blog, e precisa falar sobre o jogador Lionel Messi. Ao pesquisar seu nome no Google, você encontra um artigo da Wikipédia como primeiro resultado (surpresa?), e usa algumas informações que encontrou ali em seu texto.
Após colocar as informações que precisava, você coloca um link para a fonte, a Wikipédia.
O Google entende links como um atestado de confiança em uma página, por isso esse é o principal fator levado em consideração no cálculo de Domain Authority.
Se ele percebe que seu blog e diversos outros estão linkando para uma página da Wikipédia, vai assumir que as informações que estão ali são úteis, melhorando a chance de exibirem aquele resultado em suas pesquisas.
A versão em português do Wikipédia conta com aproximadamente 1 milhão de artigos, sobre os temas mais diversos. Esse número já caminha para 6 milhões na versão em inglês.
Com tanta informação disponível, é inevitável que a quantidade de links externos apontando para o domínio da enciclopédia virtual seja monstruosa.
E é um número que não desaponta: aproximadamente 5 bilhões de links externos.
Além da quantidade enorme, receber links de sites que também possuem uma autoridade de domínio alta é um indicador que sites de qualidade confiam nas informações da Wikipédia.
Em resumo: dois links para a mesma página tem peso diferente de acordo com sua fonte.
Essa é a principal razão para o Google entender que páginas do domínio wikipedia.org são uma boa fonte de informação para seus usuários. Mas não é a única.

Estrutura de site
Além de receber bilhões de links externos, a Wikipédia faz um trabalho excelente de linkagem interna. Todos os termos abordados durante os artigos que possuem um artigo próprio possuem um link.
Isso vale para nomes, empresas, acontecimentos históricos, datas, instituições, lugares. A lista é grande.
Com uma linkagem interna tão eficiente, fica mais fácil para o Google fazer um mapa da estrutura do site, e entender a relação entre páginas. Fica mais fácil também para quem está lendo os artigos e deseja procurar informações sobre temas citados durante a leitura.
Ter uma boa estrutura de site contribui para aumentar a autoridade de um domínio, e ajuda a Wikipédia a se manter no topo.
Links para fora da Wikipédia
Já expliquei um pouco de como links externos têm pesos diferentes. Links vindos de sites mais relevantes, e com uma autoridade de domínio maior, pesam mais, assim como o contrário.
E quanto aos links que a própria Wikipédia coloca em suas próprias referências?
Acontece que ter links em seu site apontando para sites que tem uma autoridade de domínio muito baixa é um fator negativo.

Afinal de contas, por que você quer colocar como referência um site que recebe poucas visitas, que não retém visitantes, que não é atualizado e que não recebe links externos?
Mas a Wikipédia é uma enciclopédia colaborativa. Qualquer pessoa pode acrescentar informações em artigos existentes, ou criar artigos novos para temas que não tem uma página própria ainda.
Com isso, seria impossível controlar de onde vêm as referências utilizadas. A Wikipédia pode estar linkando para milhares, se não milhões de sites, que poderiam jogar a sua autoridade de domínio no chão.
Ainda sim eles possuem números impressionantes nesse quesito. Como?
É possível dizer aos motores de busca que você não quer que aquele link conte para calcular sua autoridade!
No Follow
O No Follow é um atributo em HTML que pode ser colocado em um link, que basicamente diz ao Google e as outras ferramentas de busca que você tem intenção de que aquele link conte para sua autoridade de página e de domínio.
O link não deixa de ser clicável: você continua podendo clicar e chegar a página apontada. Entretanto o valor desta página não influenciará na sua avaliação.
Ao colocar este atributo em links que apontam para fora de seu domínio, a Wikipédia consegue se proteger, mesmo possuindo diversas referências que apontam para sites de baixa qualidade.
Bom, acho que já ficou claro como a Wikipédia atingiu um Domain Authority tão alto. Mas isso faz com ela apareça em todas as páginas de busca?
Para qual tipo de busca a Wikipédia ranqueia?
Sim, nem todas as buscas no Google são iguais. Elas seguem padrões, e entendendo estes padrões é possível chegar a três tipos de buscas principais.
Navegacional
Esta pesquisa acontece quando a pessoa já sabe onde deseja chegar, e está apenas desejando o link para chegar lá.
Acontece muito quando você quer chegar até o Facebook, por exemplo, e digita ‘facebook’ em seu navegador. Você é direcionado para uma página de respostas que te dará o link para login na rede social como primeiro resultado.
Transacional
A intenção aqui é realizar alguma transação comercial. Seja achar uma loja, comprar um produto online, ou contratar um serviço.
Informacional
Como o nome sugere, é a busca que tem como objetivo conseguir mais informações sobre um determinado tema.
Como você deve imaginar, a grande maioria das pesquisas que oferece como resultado um artigo da Wikipédia faz parte desse último tipo de pesquisa, a Informacional.
Faz sentido se pensarmos nos conteúdos encontrados na enciclopédia. Normalmente ligados a explicações técnicas e informações históricas, os artigos sempre buscam dissecar o assunto em questão, estruturando o tema em capítulos.
Presente em grande parte das buscas informacionais, e ranqueando no top 3 para grande parte das palavras-chave desta categoria de busca, fica a questão:
Os resultados da Wikipédia são necessariamente os melhores?
O nível de ‘confiança’ do Google na Wikipédia faz com que seja difícil encontrar buscas informacionais em que a enciclopédia não esteja presente na primeira página.
Se um site tem sua autoridade de domínio alta, ele tem uma probabilidade maior de ranquear bem em pesquisas, mas não garante que vai ocupar as primeiras posições, ou se manter nelas.
Isso por que o Google ranqueia páginas, não sites.
No fim do dia, se um conteúdo é o melhor para as necessidades da sua persona, ele vai ranquear em primeiro. É por isso que roubar uma primeira posição da Wikipédia é um trabalho árduo, mas possível.
A Rock Content passou por isso quando começou a brigar pela palavra-chave ‘marketing’, a alguns anos atrás.
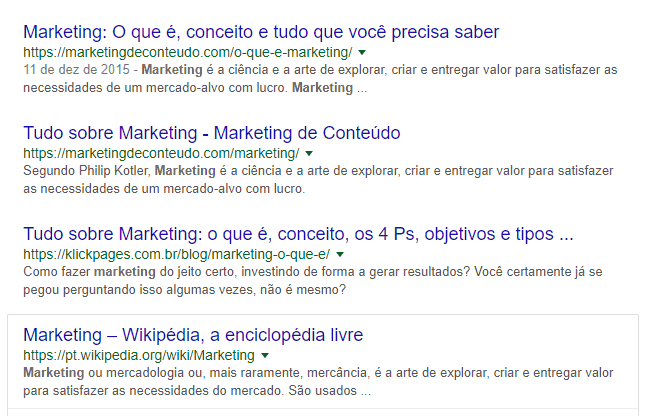
Contra um domínio tão forte, é preciso entender a intenção de busca do usuário, e colocar a mão na massa para produzir um conteúdo que vá além da Wikipédia.
Temos o processo mais detalhado neste post completo, caso você esteja querendo chegar ao lugar mais alto da Serp!
A questão aqui é: todo conteúdo tem espaço para melhora.
Se você produzir um conteúdo mais completo, ou que atenda melhor a necessidade da pessoa que buscou pela palavra-chave, é questão de tempo até começar a receber mais visitas, ter mais tempo na página, e receber mais links externos que o conteúdo da enciclopédia.
O Google, e os outros motores de busca, não vão demorar a perceber que seu conteúdo está performando melhor, e ele vai subir de posições.
Como vimos ao longo deste artigo, existem diversas razões para encontrarmos a Wikipédia no topo de tantas páginas de pesquisa. Enquanto produzir 1 milhão de artigos para seu blog está fora de alcance, temos várias lições que podemos aplicar em nossos negócios.
Lições para aprender com a Wikipédia
O que a Wikipédia faz, direta ou indiretamente, que serve de exemplo para qualquer blog ou site que queira dominar o Google?
- Invista em produção de conteúdo;
- Garanta que cada conteúdo traz aquilo que sua persona precisa;
- Trabalhe em uma boa estrutura de site;
- Link Building é rei;
- Mantenha seus artigos atualizados.
Gostou de descobrir porque a Wikipédia tem as primeiras posições no Google? Então não deixe de conferir o nosso material completo sobre SEO!